ODPS技術架構解析及其在企業級大數據開發中的實踐應用
在當今數據驅動的時代,大規模數據處理平臺已成為企業數字化轉型的核心引擎。阿里巴巴集團自主研發的ODPS(Open Data Processing Service,后更名為MaxCompute),作為其大數據計算的核心產品,憑借其強大的計算能力、穩定的服務性能以及完善的安全體系,在國內外眾多企業的大數據實踐中扮演著關鍵角色。本文將深入剖析ODPS的技術架構,并結合實際開發經驗,探討其在企業級應用中的實踐路徑。
一、ODPS核心技術架構剖析
ODPS的架構設計遵循了經典的分布式系統理念,旨在提供海量數據的存儲與計算能力。其核心可劃分為四大層次:
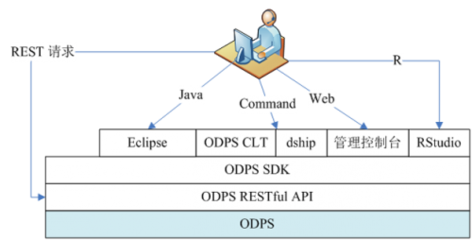
- 接入層:作為用戶與平臺的交互入口,提供多種接入方式,包括Web控制臺、命令行工具(odpscmd)、以及豐富的SDK(支持Java、Python、PHP等),滿足不同場景和開發習慣的需求。它集成了完善的身份認證與權限管理(RAM)體系,確保數據訪問安全。
- 邏輯層:這是ODPS的“大腦”,負責解析和優化用戶提交的任務。主要包括:
- SQL引擎:兼容標準SQL語法(并進行了大量擴展),將用戶的SQL查詢語句編譯成高效的分布式執行計劃。
- MapReduce/Graph/Spark引擎:提供更靈活的編程模型,用于處理復雜的迭代計算、圖計算和流處理等場景。
- 優化器:基于代價的優化器(CBO)對執行計劃進行深度優化,包括謂詞下推、分區裁剪、Join優化等,極大提升計算效率。
- 計算與調度層:該層負責將邏輯執行計劃轉化為物理任務,并進行分布式調度與執行。其核心是伏羲(Fuxi)分布式調度系統,它統一管理著龐大的集群資源,能夠實現數萬級計算節點的協同工作,自動處理節點故障,保證任務的穩定運行和高資源利用率。
- 存儲層:基于自研的盤古(Pangu)分布式文件系統構建。盤古采用多副本機制保障數據的高可靠性,并針對大數據場景做了大量優化,支持高效的數據壓縮和列式存儲(ORC、Parquet格式),為上層計算提供高吞吐、低延遲的數據讀寫能力。數據以“項目(Project)-表(Table)-分區(Partition)”的三級結構進行組織,便于管理和高效查詢。
這種分層解耦的架構,使得ODPS具備了極佳的彈性擴展能力和穩定性,能夠從容應對EB級別的數據量和復雜的計算任務。
二、ODPS在企業級大數據開發中的核心應用實踐
基于其強大的技術架構,ODPS在企業數據倉庫建設、數據湖分析、機器學習及數據挖掘等領域有著廣泛應用。以下結合CFANZ社區及業界常見實踐,幾個關鍵應用場景:
- 構建企業級數據倉庫(EDW):ODPS是構建云端數據倉庫的理想選擇。企業可以將來自各業務系統(如交易日志、用戶行為、ERP等)的數據,通過數據集成工具(如DataWorks的數據同步)定時或實時地匯聚到ODPS中。利用其SQL能力,可以高效地進行數據清洗、維度建模(如星型模型、雪花模型),形成主題明確、結構清晰的數據集市和匯總層,最終為BI報表、即席查詢提供統一、可信的數據服務。
- 大規模日志分析與用戶畫像:對于互聯網企業產生的海量用戶行為日志,ODPS的批處理能力優勢明顯。通過編寫SQL或MapReduce程序,可以快速完成PV/UV統計、路徑分析、漏斗模型計算等。結合其UDF(用戶自定義函數)和UDAF(用戶自定義聚合函數)功能,可以靈活地構建復雜的用戶標簽體系,實現精準的用戶畫像,為個性化推薦和精準營銷提供數據支撐。
- 機器學習與數據挖掘平臺:ODPS集成了PAI(Platform of Artificial Intelligence) 機器學習平臺,提供了從數據處理、特征工程、模型訓練到在線預測的全流程支持。數據科學家可以在ODPS中直接使用SQL或PyODPS進行特征提取,然后利用PAI提供的豐富的算法組件(包括傳統統計模型和深度學習框架)進行模型訓練。訓練好的模型可以一鍵部署為在線服務,形成完整的數據智能閉環。
- 成本與性能優化實踐:在企業應用中,成本控制與性能調優至關重要。常見的ODPS優化實踐包括:
- 數據層面:合理設計表分區和生命周期,及時刪除過期數據;選擇合適的數據壓縮格式和列類型;對小表使用“廣播”優化等。
- 計算層面:避免使用
SELECT *,明確指定所需列;優化Join條件,優先使用分區鍵;利用CBO的統計信息進行查詢重寫;對復雜作業進行分步驟計算,中間結果使用臨時表緩存。
- 任務調度:利用DataWorks等工具實現依賴關系的可視化編排,錯峰執行高資源消耗任務,提升整體集群利用率。
三、與展望
ODPS作為經過阿里巴巴超大規模業務場景錘煉的大數據平臺,其技術架構成熟、生態完善、服務穩定。采用ODPS不僅可以快速獲得處理海量數據的能力,還能借助其上層工具鏈(如DataWorks、Quick BI)快速構建端到端的數據解決方案。
隨著云原生和湖倉一體概念的深入,ODPS也在持續進化,例如加強實時計算能力(與Flink、Hologres融合),支持更多開源生態格式(如Iceberg),以及提供更細粒度的資源組隔離與彈性計費模式。ODPS將繼續降低大數據技術的使用門檻,賦能更多企業挖掘數據價值,驅動智能決策與業務創新。
(本文由Andy@根據ODPS公開技術資料及社區開發實踐經驗,發布于CFANZ社區,旨在進行IT技術分享與交流。)